For a distributed system to work, it has to move information from machine to machine. No single machine is responsible for the system as a whole. But yet all information is somehow related to all other information. So it stands to reason that a major concern of distributed system infrastructure is moving data to the machines that need it. This also ends up being one of the most significant challenges.
Remote procedure calls
The simplest way to move information from one box to another is through a remote procedure call (RPC). An RPC models the way that code calls functions in a program. The caller passes a packet of information to the recipient as parameters. It then waits for the recipient to do whatever it needs to do, even if the recipient is going to call another procedure. And then the recipient returns another packet of information in the results. This model works fine for programs, but it has some drawbacks in distributed systems.
RPCs are synchronous. The calling machine allocates some resources, typically a thread, that stand waiting for the recipient to respond. Sometimes the request is a query, where the caller is waiting for the results before it can continue processing. Other times, it is a command, informing the recipient that it needs to take action. Even if the call is a command that returns void, the caller must wait for the response. If it doesn’t receive the response, it doesn’t know that the intended recipient received the call. So it has to either fail the request or retry the RPC.
RPCs are also unreliable. A local method call in a program cannot typically fail to reach the recipient. But a remote procedure call can get dropped, it can time out, or it can be corrupted. This might not just happen to the request, but also the response. If the call fails, the caller has no way of knowing which was lost. If it was the request, then a retry would be safe. But if it was the response, then a retry might lead to duplication.
Advantages of message queues
Message queues address both of these problems. First, they are asynchronous. After the message has been queued, the caller doesn’t wait for it to be processed. It can free up that thread for handling additional work. If the caller expects a response, then the caller must pull response messages from a second queue. While this complicates matters, we have tools (for example sagas) to address this new complexity.
Message queues are also reliable. Once the sender is sure that the message is in the queue, it can be confident that it will be received once and only once. Message queues typically have a two-phase API for receipt: first the recipient gets the message, and then it commits. If a problem occurs before the commit phase, then the message is “put back on” the queue (in actual fact, it never truly left; it only looked like it did). This two-phase receipt ensures that a message will be processed once and only once. It is no longer the concern of the sender.
Disadvantages of message queues
Message queues and RPCs do have one feature in common. They are both one-to-one in nature: they transmit information from one sender to one recipient. Like a caller of an RPC, the message sender has some idea about the system for which the message is intended. A queue is not a broadcast mechanism. When one recipient receives the message, it is no longer available for others to pick up. We have additional tools (for example dispatchers) to support one-to-many scenarios.
Message queues create additional operational complexity. Every queue must be created, configured, and monitored. Every sender and recipient must be configured with the location and name of each queue. We have created tools (for example service busses) to manage this complexity, but they do not eliminate it entirely.
Message queuing in historical modeling
Historical modeling puts the idea of the message queue into the model itself. Every fact is potentially a queue. A subsequent fact can be published to this predecessor.
Take, for example, a medical claims processing service.model
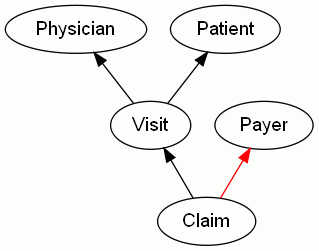
fact Physician {
unique;
}
fact Patient {
unique;
}
fact Visit {
Physician physician;
Patient patient;
date dateOfService;
}
fact Payer {
unique;
}
fact Claim {
publish Payer payer;
Visit visit;
}
In this model, the Payer fact acts as a queue. A Claim is published to that queue. This is indicated in the factual code with the publish keyword, and in the diagram with a red arrow.
When the payer processes the claim, it responds with a remittance advice.model
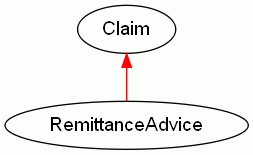
fact RemittanceAdvice {
publish Claim claim;
decimal amount;
}
The RemittanceAdvice fact is published to the Claim. The practice subscribes to the claim in order to receive the response.
To make the Payer act as a queue, it needs to query for all of the unprocessed claims:
fact Payer {
unique;
Claim* unprocessedClaims {
Claim c : c.payer = this
where not c.processed
}
}
The query depends upon the processed predicate:
fact Claim {
publish Payer payer;
Visit visit;
bool processed {
exists RemittanceAdvice a : a.claim = this
}
}
Adding a RemittanceAdvice causes the processed predicate to become true, thus removing the Claim from unprocessedClaims.
Advantages of historical message queues
The historical modeling message queue pattern has some advantages over traditional message queues. Most significantly, the queue is no longer coupled to a physical location. The practice didn’t know the location or name of the payer’s queue. Neither did the payer know the location of the practice. As long as the sender and recipient share a common upstream server, the claims and remittance advice will flow to the interested parties.
We also have the advantage of creating queues on the fly with no operational overhead. We can add a new payer to the system as easily as creating a new object. Each payer’s service subscribes to its own queue, without the need for configuration. And consider the operational nightmare of configuring a new response queue per practice, let alone per claim as we’ve done in this model.
Disadvantages of historical message queues
On the other hand, historical modeling has one significant disadvantage as compared to message queues: it is impossible to ensure that only one recipient handles each message. The two-phase receipt of a traditional message queue lets one service lock a message. Other services pulling work from the same queue will not receive it unless the first service fails. This is an effective technique for load-balancing backend services.
The rules of historical modeling forbid locking. To balance the load among competing backend systems, you must bridge a historical model into a more traditional message queue. The bridge pushes a message onto the queue for each unprocessed fact, and then creates a new fact marking it as received. This bookkeeping fact is not intended for application use, and is typically not published. The historical database and the message queue must be compatible so that they can participate in the same transaction, thus ensuring reliability.
Conclusion
Message queues offer significant advantages over RPCs in distributed systems. Whereas RPCs are synchronous and unreliable, message queues are asynchronous and reliable. They add complexity both to application design and operations, but that complexity can be managed.
Historical modeling supports the concept of a message queue through the publish keyword, predicates, and queries. It can ease some of the operational complexity, since it decouples senders and recipients from queue location. And since any fact can be a queue, operational overhead is not incurred to add a new queue. However, historical modeling does not support locking, so additional work is required to implement a load-balancing scenario.