In the first installment of The Learning Journey, I described a system. The original architecture of that system appears in Figure 1. The new architecture is in Figure 2.
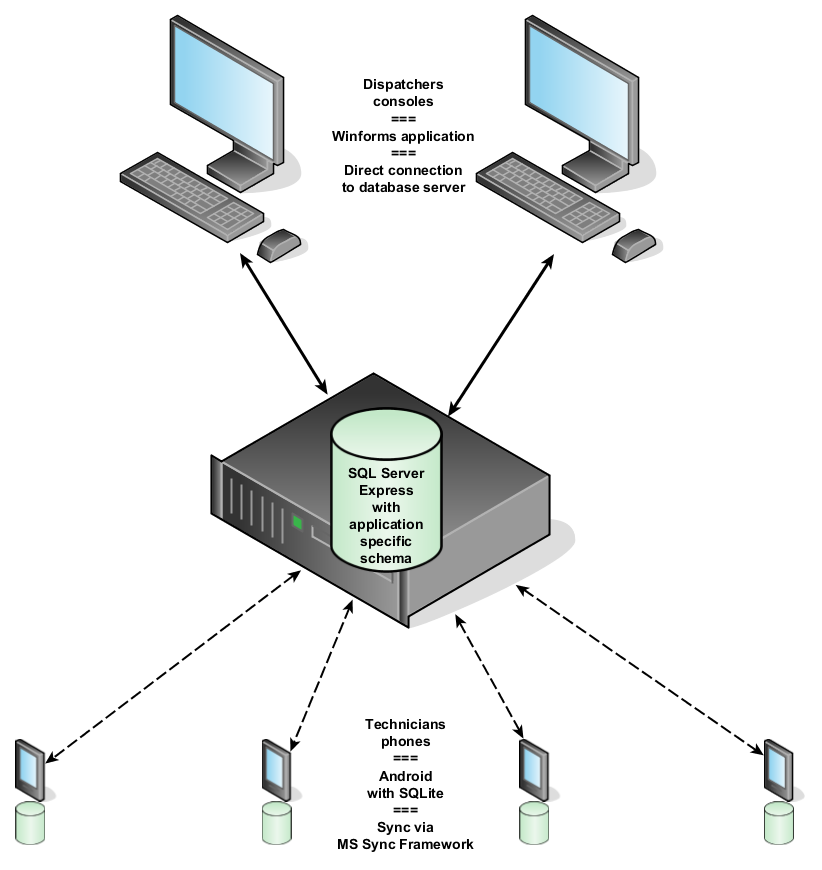
Fig.1: The old architecture that came with several issues which I explained in episode 1.
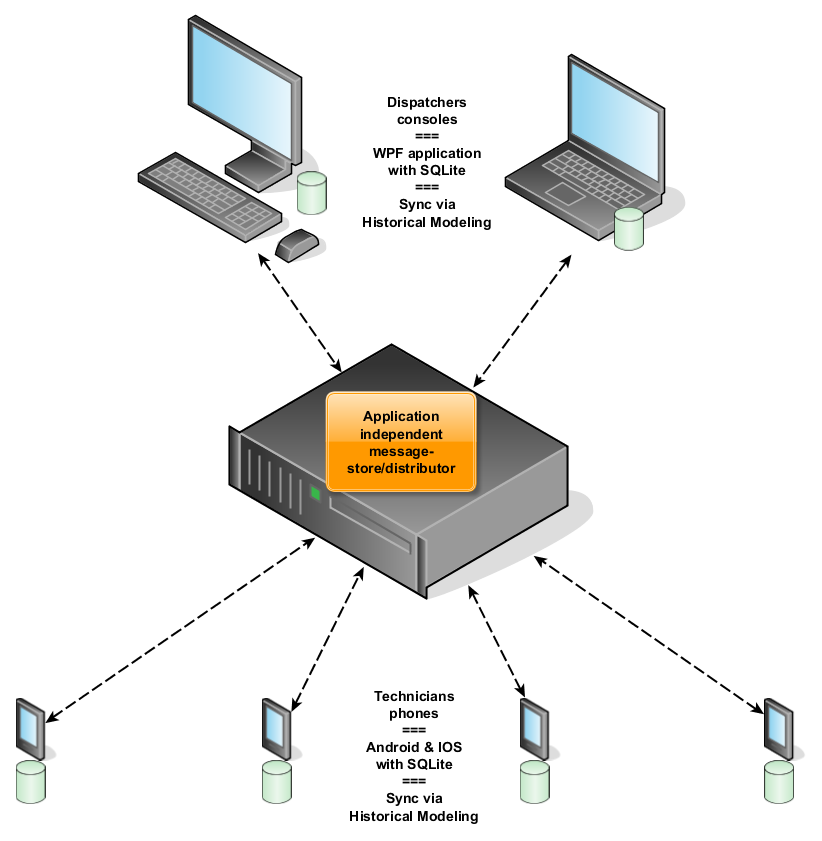
Fig.2: The new architecture.
Looking at Fig.1 and Fig.2, let’s find the differences between the old and the new architecture and, more importantly, the consequences:
The fundamental change in the new architecture is that our data structure/storage follows the Historical Modeling concept. This decision has very important consequences:
- Because of immutability, the synchronization of the data now becomes so much easier. And we don’t need any closed-source external technology/components anymore, so we can get rid of the old and abandoned MS Sync Framework.
- With the MS Sync Framework gone, the need for the SQL Server database (and possible licensing issues once we outgrow the express edition) is gone as well.
- The console application (the app for the dispatchers, remember) gets its own local database, which will be synchronized with the rest of the system. Hence, increased reliability, improved response time, decreased server load and the console can be used off-line “on the road”.
- Keeping history is no longer difficult as it is a natural consequence of using Historical Modeling. So if we want to keep a customer’s new address as well as its old address, no problem (except perhaps for the new GDPR legislation in Europe).
- Even being offline one can make decisions. So as well the workers as the dispatchers can safely make corrections to previous input, even if they are offline. If ever multiple people make conflicting corrections or changes, these conflicts can be resolved later by anyone at any time. And the fact that there was a conflict and how it was resolved will always be available for traceability.
- The central database server with application specific schema can be replaced by an application independent message store/distributor. Hence, very loose coupling which should allow us to upgrade the system relatively easy.
All my wishes fulfilled? Not yet. The old architecture had one very important shortcoming that new architecture doesn’t solve (yet). I even forget to mention that one in the first episode, but reality once again reminded me about it last week. We have a single point of failure: the central database server in the old architecture, and the distributor in the new architecture. It would be nice if we could have a continuous data backup of the messages on the distributor. It would even be better if we could have a cold standby distributor. And the ultimate would be to have a hot standby distributor in a different data centre. I have been thinking about it for a while now: instead of keeping the messages on the clients queue until the distributor has saved the message, we could keep them on the clients queue until at least two distributors have saved the message. However the bookmark-related counter on each distributor complicates things. I think we need Michael’s input on this one… Michael HELP.
Note from Michael: Not to worry. This problem has solutions. Let’s discuss some of the options, and I’ll provide documentation for the readers.
So the basic architecture is clear, now it’s time for the real work. In the next episode we’ll start building our historical model.
Want to prepare? Have a look at How Not to Destroy Data. For those who have a Pluralsight subscription and finished the Collaboration course, Occasionally Connected Windows Mobile Apps: Enterprise LOB might be of interest to you.